推特改用Kafka取代Pub/Sub大量转推发文时能节省75%运算资源

推特最近把原本内部开发的Pub/Sub系统EventBus更换成Apache Kafka,除了在成本上,当有许多使用者都要转推发文的情况下(资料处理上称为fan-out),能节省高达75%的资源外,由于Kafka庞大社群的资源,修复错误和增加新功能更快,也更容易找到系统维护工程师人选。
Apache Kafka是一个开源分散式串流平台,能以高吞吐量低延迟方式传输资料。Kafka的核心是基于日誌建构的Pub/Sub系统,具有可水平伸缩和容错性,是用来打造即时新闻系统的理想选择。但其实推特在几年前就已经使用过Kafka,推特发现当时Kafka 0.7版本,有几个不适合他们使用情境的缺点,主要是在追赶读取(Catchup Reads)期间的I/O操作数限制,也欠缺耐久性和複製功能。
由于当时使用Kafka的这些限制,推特基于Apache DistributedLog,打造了自己的Pub/Sub系统EventBus,以应付推特快速发布突发新闻、对使用者提供相关广告,以及其他即时使用案例的需求。
时至今日,硬体和Kafka专案在经过时间的发展,推特之前遇到的问题,都已经获得解决。SSD的价格已经足够低廉,有助于解决之前在HDD上遇到随机读取先前I/O的问题,而且伺服器NICs具有更大的频宽,使得EventBus的分割服务和储存层的好处消失。新版的Kafka现在还支援资料複製,提供推特需要的资料耐久性保证。推特表示,驱动他们把Pub/Sub系统从EventBus搬迁到Kafka上,主要是考量成本以及社群两个原因。
在推特决定要搬迁Pub/Sub系统到Kafka之前,团队花了数个月评估,他们在Kafka上运作相近于EventBus上的工作负载,包括耐久写入、长尾读取(Tailing reads)、追赶读取以及高扇出读取(High Hanout Reads),还有一些灰色故障的情境。从资料串流消费者读取讯息的时间戳差异来衡量,无论吞吐量如何,Kafka的延迟都明显较低,推特提到,这可以归因成三个原因,第一个,由于在推特原本使用的EventBus,服务层和存储层是分离的,因此产生额外的跳跃(Hop),而Kafka只用一个程序处理储存和请求服务。
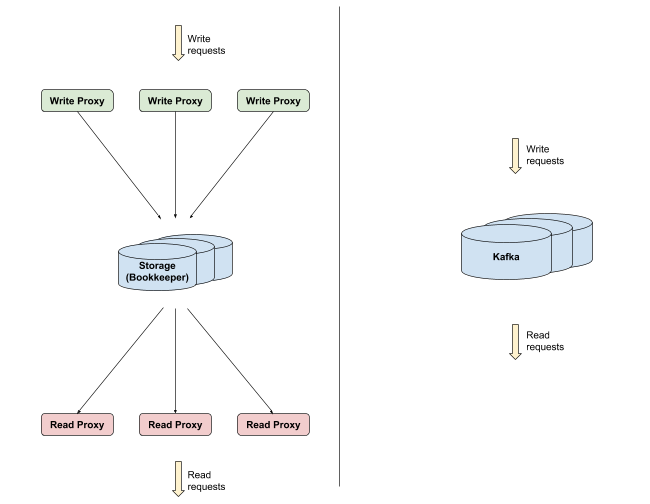
第二个原因,EventBus明显地阻止对fsync()呼叫写入,但是Kafka却仰赖作业系统背景进行fsync()呼叫。第三个原因是,Kafka使用零複製(Zero-copy)。因此从成本的角度来看,EventBus需要服务层和存储层的硬体,分别针对高网路吞吐量和硬碟进行最佳化,但Kafka只需要使用单一主机,推特提到,显然EventBus需要更多的机器才能达到和Kafka相同的工作负载。
单一资料串流消费者的使用案例,Kafka可以节省68%的资源,当有多个使用者发文并转推给他们所有友人时的fan-out情况下,推特估计,则能节省高达75%的资源。推特表示,由于他们使用案例fan-out效应不够极端,在实作中不值得分离服务层,特别是考虑到现代硬体上的可用频宽,否则在理论上EventBus应该更有效率。
除了成本上的考量,Kafka庞大的支援社群也是一大优势。在推特中,维护EventBus系统的只有8名工程师,但是Kafka专案现在却有数百人进行维护,帮忙修复错误和增加新功能。推特预计在EventBus增加的新功能,像是串流函式库、至少一次HDFS工作管线以及一次性处理都已经在Kafka中具备了。
此外,在客户端或是伺服器发生问题时,开发人员可以参考其他团队的经验,快速的解决问题,而且也因为Kafka是一个热门专案,因此了解Kafka的工程师数量也比较多,方便招聘系统工程师。在接下来的几个月内,推特计画开始把使用者从EventBus迁移到Kafka上,以降低营运成本,并且让使用者获得Kafka提供的其他功能。
免责声明:本文由用户上传,如有侵权请联系删除!
猜你喜欢
- 庆余年哪集是范闲背诗的(庆余年范闲背诗第几集简介介绍)
- 西游记里面的故事简介(西游记的故事有哪些简介介绍)
- dnf男街霸三觉(dnf86级男街霸\/千手罗汉\/暗街之王二觉刷图加点)
- 产品整体概念的主要内容是什么(什么是产品整体概念简介介绍)
- 英雄联盟手游内测怎么申请内测申请攻略(LOL英雄联盟手游内测在哪申请)
- 剑灵一个南天国金币可以换多少银币(剑灵南天国铁币,银币在哪获得)
- 凯里欧文到底多高(凯里欧文的身高体重是多少简介介绍)
- 申请工伤认定所必需的材料是什么(申请工伤认定所必需的材料是)
- 生日歌歌词(蝶变新生的主题歌歌词)
- 中餐与西餐有什么区别(中餐与西餐有什么区别)
- 索爱k506c(用索爱k510的进一下)
- 我们结婚了初恋夫妇表演舞台(我们结婚了初恋夫妇(泰民)
最新文章
- 中国好声音如果没有你李昊瀚(山野中国好声音李昊瀚唱的那么好为什么淘汰)
- 被套的尺寸是多少(被套尺寸一般是多少简介介绍)
- 怪物x联盟复刻版攻略(怪物x联盟复刻祥云马)
- 阳历是快的还是慢得(快的和慢的哪个是阳历简介介绍)
- 英雄联盟赵信特战先锋(特战先锋德邦总管赵信)
- 凤凰传奇有一首歌叫什么(凤凰传奇有一首歌歌词有)
- 为什么腾讯视频看不了直播(腾讯lpl视频看不了怎么办)
- Blue(Da(Ba Dee) 歌词)
- 联想z475开机黑屏(联想Z475开机超慢怎么回事)
- 吴建豪舞林大会跳的舞(2011舞林大会吴建豪怎么没有看见进复赛)
- 海清结婚了吗现在怎么样了(海清结婚了吗)
- 开十字绣店到哪里进货(开十字绣店在哪里进货怎么进货呢)
- 卫庄大战六剑奴是哪一集(卫庄哪集说的六剑奴是值得一战的对手)
- 微信六年来第一次开始“变脸”为什么
- iphone怎么看已连接wifi密码(iPhone怎么越狱啊)
- 求K233次列车(15车厢的座位号)
- 能链综合能源港里的充电站为何成为香饽饽
- 鸡蛋怎么做比较有营养(鸡蛋怎么做比较好吃)
- lol手游霞怎么出装(LOL新英雄霞与洛逆羽霞如何出装霞怎么出装)
- 穿越火线什么时候上架(穿越火线什么时候能玩)
- 北比臼舅怎么读(北比臼日怎么读)
- 创世之柱任务有什么用(创世之柱任务怎么做)
- 徐磊的歌曲(写给你的歌 徐磊乐演唱作品)
- 广州市经济适用住房准购证明怎么办理(如何取得广州市经济适用住房准购证明)