谁说公有云服务跑不动HPCAWS持续提供多种解决方案重新在公有云环境组建适合高效能运算的IT基础架构
李宗翰摄影
【美国拉斯维加斯现场报导】原本是学术领域较常用到的高效能运算(HPC)技术,如今随着大数据分析与人工智慧的走红,开始日益受到重视,但过往我们可能必须在设有超级电脑的特定环境,才能发展相关的应用,然而,随着运算技术的进步,如今我们可以透过串连多台x86伺服器,搭配GPU加速卡,也能支援高效能运算的各种应用。
然而,如果要在伺服器虚拟化平台、云端服务的环境,执行高效能运算,至今似乎仍相当少见,因为大家总会担心在这样的虚拟、多租户共享的架构下,运算和I/O效能都会有折损,如何还能支撑高效能运算的使用场景。
不过,现在有公有云业者想要打破这个刻板印象,希望吸引更多有这方面需求的用户,也能积极考虑採用公有云环境。举例来说,今年AWS在年度全球用户大会re:Invent的第一天,AWS全球基础设施与客户支援副总裁Peter DeSantis就以此为题,讲述他们现在其实已经能够负荷这样的应用情境。
为何现在AWS提供的IT基础架构,已做到能让一般用户向其租用超级电脑等级环境的需求?Peter DeSantis列出了他们重新发明超级电脑架构的历程。

首先,是建立了高速、低延迟、大容量的资料中心网路。经过6年的发展,AWS目前提供的执行个体(虚拟机器或裸机的租用服务),有了相当大的进步,不只是虚拟CPU的颗数增加了1倍多,尤其是网路规格就成长了10倍(10Gb vs. 100Gb),在整体网路负载的能力上,更是差距20倍以上(460 Tbps vs.10,600 Tbps)。

第二,将所有虚拟化作业都卸载到AWS发展的晶片与硬体技术。这里所指的硬体技术,主要是AWS与2015年併购的Annapurna Labs研发的Nitro Controller架构,在这样的系统之下,EC2所有虚拟化功能都是执行在Nitro Controller,网路流量虽然转为虚拟化,但延迟度、变化性、成本均可降到最低。目前而言,EC2的C5和C5n都是基于这个技术而成的执行个体。

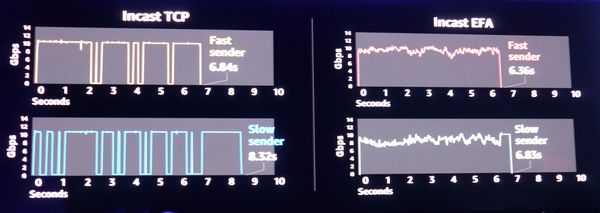
第三,AWS发展出硬体最佳化、核心旁路的网路堆叠(Kernel Bypass Network Stack)。他们在2018年的re:Invent大会宣布推出的网路介面Elastic Fabric Adapter(EFA),就是一个例子。相较于原本只用TCP来进行Incast的传送,改用EFA来处理,可缩短传送较快者与传送较慢者之间的传输时间差距。
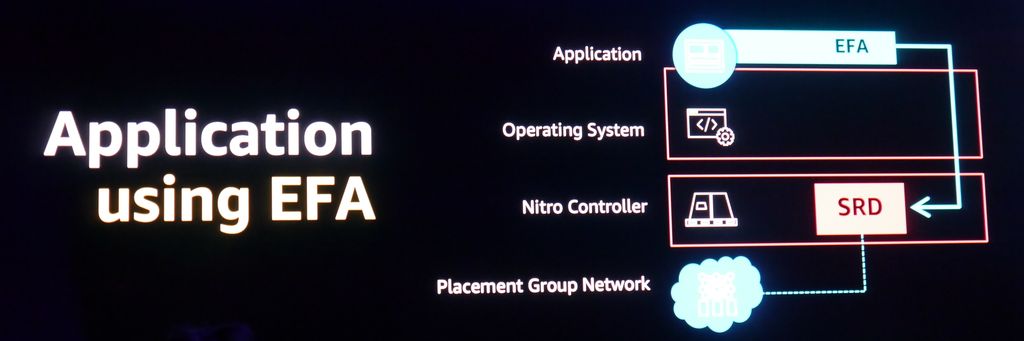
第四,整合常用的程式库与应用程式。以EFA而言,不只是Amazon Linux支援,也有其他软体或应用程式介面支援,像是Ubuntu、Red Hat、SUSE、OpenFOAM、LS-DYNA、Open MPI。

最后,要有很好的使用案例。Peter DeSantisu也举出几个企业应用实例,主要是销售风扇的Big Ass Fans公司,以及与AWS合作的F1赛车。

免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
【云南彝族阿诗玛传说】一、“云南彝族阿诗玛传说”是云南省彝族地区流传已久的一则民间故事,具有深厚的文化...浏览全文>>
-
【云南野当归介绍】云南野当归,学名Angelica polymorpha,是伞形科当归属的一种野生植物,主要分布于中国西...浏览全文>>
-
【云南洋芋焖饭的做法】云南洋芋焖饭是一道具有地方特色的家常美食,以土豆(洋芋)为主料,搭配米饭、肉类或...浏览全文>>
-
【云南雪山玉龙雪山冷不冷】玉龙雪山位于云南省丽江市,是滇西北著名的旅游景点之一。许多游客在计划前往玉龙...浏览全文>>
-
【京东盛京信用卡额度是多少】京东盛京信用卡是由京东金融与盛京银行联合推出的联名信用卡产品,主要面向京东...浏览全文>>
-
【京东申请退款怎么取消】在使用京东购物时,有时可能会因为商品问题、误下单或价格变动等原因,想要取消已经...浏览全文>>
-
【京东申请退款多久到账】在网购过程中,用户经常会遇到商品质量问题、发错货或不满意的商品,这时候申请退款...浏览全文>>
-
【京东上征信吗】在日常生活中,越来越多的人开始关注自己的征信情况。尤其是在使用电商平台如京东时,很多人...浏览全文>>
-
【京东上怎么投诉商家】在京东购物过程中,如果遇到商品质量问题、发货延迟、描述不符或服务态度差等情况,消...浏览全文>>
-
【京东上怎么买正品吗】在京东购物,很多消费者最关心的问题就是“怎么买正品”。虽然京东本身是正规平台,但...浏览全文>>